10. RNN - 딥러닝을 이용한 문서 분류
10.1. 왜 RNN일까?
RNN(Recurrent Neural Networks)
- 시계열 데이터(=어떤 변수의 값이 시간에 따라 변화하는 것)를 다루기 위한모형으로 알려져 있음.
- 시계열 예측모형에서 가장 중요한 가정 - 앞의 값들이 뒤의 값에 영향을 미친다는 것.
- 시계열 모형에서는 입력으로 일정 기간의 연속된 값을 사용함.(순차적으로 영향을 미쳤다는 점이 입력의 중요한 가정임)
=> RNN은 이러한 순차적인 영향을 표현하기 위한 모형임

-> 이 식에서 '과연 RNN 신경망 모형의 입력은 몆 개인가?' -> 내가 정한 수의 입력
[RNN이 문서 분류에 적합한 이유]
- RNN은 앞에서부터 순차적으로 미치는 영향을 계속 축적하는 모형이기 때문에, 문장에 있는 단어의 순서를 무작위로 바꿔 놓으면 의미를 정확하게 파악하지 못할 수 있음.
- RNN은 딥러닝의 대표적인 문제인 경사소실 문제가 심각한 모형이지만, 개념적으로 볼 때 문맥의 파악을 잘 반영하며 텍스트 마이닝에 딥러닝을 적용하는 의미 깊은 출발점이 됨.
[RNN의 문서 분류 적용방안]
- 순환신경망: 주어진 입력값들의 순서가 의미가 있을 때(=입력값이 앞의 입력값들에 영향을 받는 경우)에 사용하는 신경망
-근본적으로 문장은 단어들의 순서에 따라 문맥이 결정되므로, 문맥 파악에 순환 신경망이 사용됐다고 할 수 있음.
ex) 문서 분류에 RNN을 적용하는 예
1. 각 단어는 먼저 원핫 벡터로 표현됐다가 짧은 길이의 밀집 벡터로 다시 변환되어 RNN 모형에 입력으로 사용됨
- 모형은 입력이 6개이고, 분류하려는 문서는 총 9개의 단어로 되어 있다고 한다면, 문서의 앞쪽 단어 세 개를 잘라내야 함.
2. 문서는 [6,4] 크기의 2차원 행렬로 표현되고, 이 값이 뒤에 있는 순환신경망의 입력으로 사용됨.
3. 각 단어의 정보는 은닉 노드로 압출되고 이 과정에서 앞 단어가 뒤 단어에 미치는 영향이 순차적으로 축적되어 전달됨.
4. 출력 노드는 모든 정보가 축적된 마지막 은닉 노드에 연결된 것만 사용 -> 마지막 출력 노드를 이용해 문서를 분류하면 됨
10.2. 워드 임베딩의 이해
단어를 RNN 모형에 입력으로 사용하려면, 원핫 벡터 -> 밀집 벡터로 변환해야 함.
WHY? -> 딥러닝에서는 기본적으로 문서를 단어의 시퀀스로 표현하고, 각 단어들은 고정된 길이의 벡터가 되야 처리가 가능함.
[워드 임베딩]
- 범주형 데이터를 분석하려면 먼저 이를 수치로 변환해야 함. -> 일반적으로 더미 변수의 이용 & 임베딩이 있음.
- 더미 변수: 0과 1만으로 범주형 데이터를 표현.
ex) 성별은 2개의 값만 가지므로 더미 변수 하나를 이용해 0과 1로 표현할 수 있음.
ex2) 더미 변수를 d1, d2, d3, d4라고 한다면, 각 더미 변수는 네 개의 혈액형을 의미하고 해당 혈액형이면 1or0으로 표현.
-> A: [1, 0. 0, 0] / B : [0,1,0,0] / AB : [0,0,1,0] / O : [0,0,0,1]
=> 이렇게 범주형 데이터를 벡터 형태의 연속된 수치로 변환하는 것 = 원핫 인코딩 / 그 결과 = 원핫 벡터
- 단어에 대해 원핫 인코딩을 수행하면 말뭉치에 사용된 단어 수만큼 더미 변수가 필요함
- 임베딩: 범주형 데이터를 연속적인 값을 갖는, 상대적으로 작은 크기의 벡터로 변환하는 작업
- 워드 임베딩: 보통 단어에 대해 원핫 인코딩을 먼저 수행하고 이를 다시 연속형 값을 갖는 축소된 벡터로 변환하는 과정
왜 단어 임베딩을 할까?:
1. 공간이나 연산의 효율
2. 대상 간의 의미적 유사도 계산 가능
3. 단어가 의미적인 정보를 함축함으로써 연산 가능해질 수 있음
4. 전이학습(기존에 학습된 모형을 새로운 환경에서 재사용함으로 학습의 속도&효과 높이는 방법) 가능
[BOW와 문서 임베딩]
- Bow / 카운트 기반의 문서 표현에서 문서는 사용된 단어들의 빈도를 벡터 형태로 표현함.
- 카운트 기반의 문서 표현은 코사인 유사도와 같은 방법으로 희소 벡터 자체로 유사도를 계산할 수 있음
[워드 임베딩과 딥러닝]
- 대부분의 딥러닝 기반의 자연어 처리 기법에서는 문서를 단어의 시퀀스로 표현함.
- BOW와의 가장 큰 차이점: 단어의 순서를 고려해 문맥을 파악한다는 점
-> 이로 인한 문서에 대한 표현 차이점: BOW에서는 문서가 1차원 벡터로 표현되는 반면, 워드 임베딩을 이용하게 되면 문서가 2차원 행렬 혹은 1차원 벡터의 리스트로 표현됨.
10.3. RNN을 이용한 문서 분류 - NLTK 영화 리뷰 감성분석
[워드 임베딩을 위한 데이터 준비]
- NLTK 데이터를 불러와서, 리뷰는 reviews에, 긍정부정에 대한 라벨른 categories에 저장
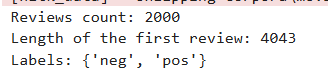
- Tokenizer 객체를 생성할 때 num_words를 이용해 모형에 사용할 단어 수를 결정할 수 있음.
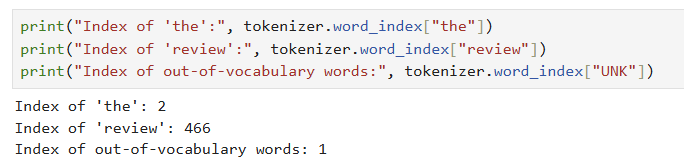
- fit_on_texts()를 수행하면 주어진 말뭉치에 대해 단어 인덱스 사전이 구축되고, texts_to_ sequencesO는 이 사전을 이용해 문서들을 인덱스의 시퀀스로 변환함

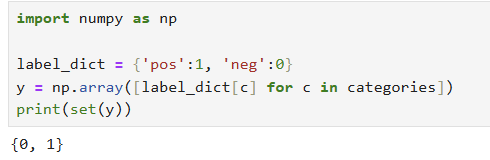
- 출력도 케라스 신경망 모형에 맞게 변환. 라벨 변경하기(0,1)
- 모형 검증하기 위해 학습 데이터켓과 테스트 데이터셋으로 분리

[RNN이 아닌 일반적인 신경망 모형을 이용한 분류]
- 로지스틱 회귀모형을 구현해서 시퀀스 정보 없이 예측을 수행해보기.

-> 이렇게 모형을 만들고, 학습 수행
- 학습 하려면 손실 함수랑 옵티마이저를 설정해야 함-> compile() 메서드
- fit() 메서드 -> 학습 데이터셋을 이용해 학습 수행.
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])-> 모형의 optimizer와 loss function 등을 지정
history = model.fit(X_train, y_train,
epochs=10,
verbose=1,
validation_split=0.2)-> 학습 수행
=> 이렇게 진행했더니 막 주르륵 학습이 시작되기 시작했다.
- 학습 종료되자, histroy에 담겨진 에포크별 성능을 그래프로 그려서 학습이 잘 됐는지 확인해보았음.
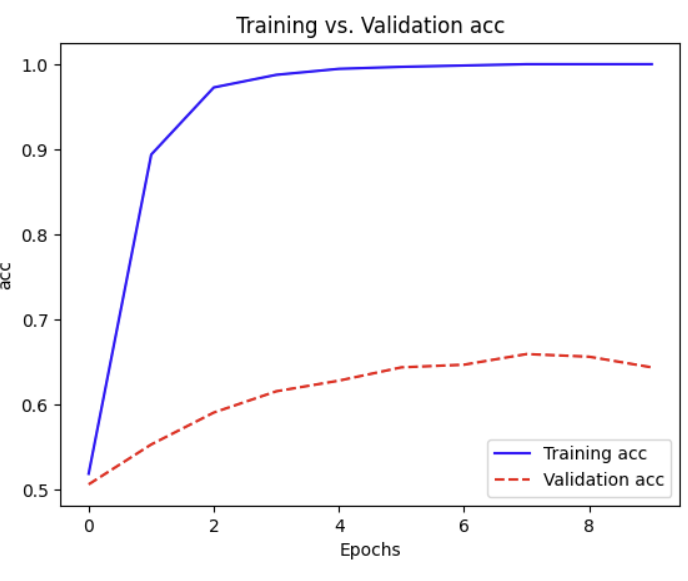
오..신기방기..
[문서의 순서정보를 활용하는 RNN 기반 문서분류]
- RNN 모형을 적용함으로써 단어의 순서(문맥의 정보)를 활용한 문서 분류 진행.
- Flatten() -> SimpleRNN() 레이어 사용
-> 이론이 복잡한 거에 비해 사용은 매우 쉽다는게 장점.
- SimpleRNNO 레이어 뒤에 DenseO 레이어를 추가 -> 최종 노드에 대해 은닉층 하나 추가해 모형 성능 높임

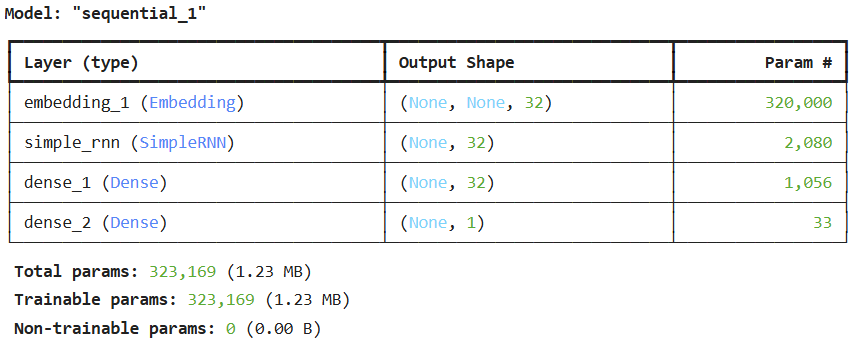
-> 학습이 거의 이루어지지 않은 것을 볼 수 있음.
- 검증 데이터셋에 대한 정확도는 0.5 근처에서 벗어나지 못하고 있음 -> 과대적합만 이루어지고 있을 뿐, 실제 학습 거의 진행 X
WHY? -> 딥러닝의 가장 큰 문제점인 경사소실에 원인이 있음. => 장기간에 걸친 시간의존성
-> LSTM이 솔루션으로 제안된 모형임
10.4. LSTM, Bi-LSTM과 GRU를 이용한 성능 개선
- LSTM의 목적: 앞부분의 정보가 뒤로 갈수록 소실되는 것을 방지하기 위해 장기의존성과 단기 의존성을 모두 표현하고 학습하는 것
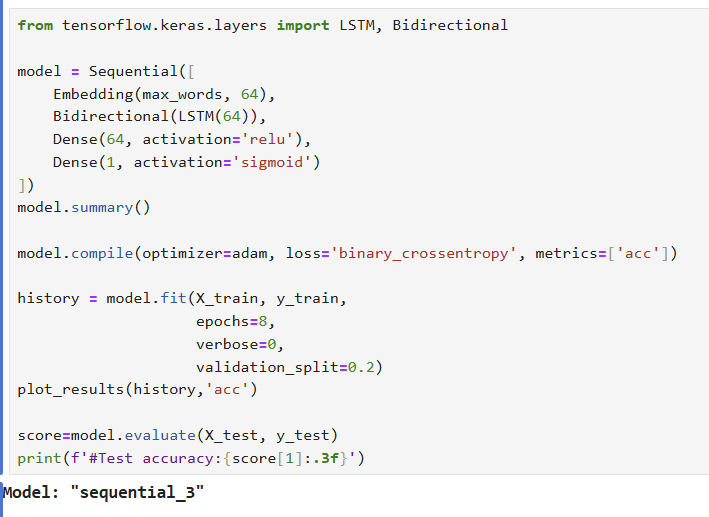
-> 결과를 보면 검증 데이터셋에 대한 정확도가 0.8까지 올라가는 것을 볼 수 있음.
- 테스트 데이터셋에 대한 정확도도 79.3%로 좋아짐.
- 학습된 모형을 이용해 결과를 예측하고 싶다면, model의 predict() 메서드를 이요한다.