14. BERT의 이해와 간단한 활용
14.1. 왜 언어 모델이 중요한가?
언어 모델: 문장 혹은 단어의 시퀀스에 대해 확률을 할당하는 모델
- 문장에 확률을 할당?: "나는 배가 고파서 밥을 먹었다." vs "나는 배고 고파서 밥을 치웠다."
-> 더 자연스러운 문장 = 전자. 더 자연스러운 문장에 더 높은 확률을 부여.
=> 잘 학습된 언어 모델은 문장을 잘 완성할 수 있다.
- 언어 모델을 이용한 학습이 갖는 의미? -> 언어 모델은 언어에 대한 이해를 높이는 학습이라고 할 수 있음.
+ 비지도 학습이 가능하다는 것도 장점.
14.2 사전학습 언어모델의 이론적 이해
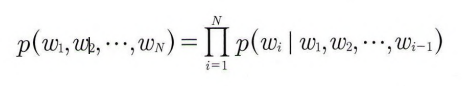
- w1, w2,…, w n 이 어떤 단어의 시퀀스 혹은 문장이라고 가정하면, 이 시퀀스가 나타날 확률은 각 단어들의 결합확률로 표현되며 식에서와 같이 조건부 확률의 곱으로 계산된다.
- p(w i | w1,w2 ---) 는 언어모델에 따라 다양한 방법으로 계산될 수 있다.
사전학습 언어모델: 미리 학습된 언어모델이라는 의미. 일반적으로 비지도 학습으로 이뤄짐.
장점1: 다양한 자연어 처 리 작업의 정확도를 크게 높일 수 있음.
장점2: 머신러닝 기반의 자연어 처 리 모형 학습의 부담을 크게 줄였음.
14.3 BERT의 구조
BERT - Bidirectional Encoder Representations from Transformers
- 트랜스포머에서 인코더 부분만 사용한 모형으로, 이 인코더의 특징은 양방향 셀프 어텐션을 구현하고 있음
- GPT(Generative Pre-trained Transformer)와 비교:
- GPT는 BERT보다 먼저 발표된 모형으로, 주로 자연어 문장 생성에 특화된 모델
-> 생성 외에 문서분류와 같은 다른 분야에서도 좋은 성능을 낸 반면 트랜스포머의 디코더 부분만 따로 떼어서 학습 모형으로 사용했기 때문에 인코더에서 디코더로의 어텐션은 생략, 셀프 어텐션은 순방향 적용

14.4 언어모델을 이용한 사전학습과 미세조정학습
- BERT의 학습 -> 사전학습 & 미세조정학습 두단계로 나뉨.
- 사전학습은 지금까지 설명한 바와 같이 언어에 대한 이해를 높이기 위한 비지도학습이고, 미세조정학습은 실제 수행하고자 하는 작업에 대한 지도학습

사전학습:
- 사전학습은 언어 모델 학습으로 구성됨 -> BERT의 사전학습은 지금까지 배운 언어 모델 학습과 차이가 있음.
- 언어 모델을 이용한 학습에서는 앞에 주어진 단어들 다음에 나올 단어의 확률을 예측하는 방식으로 학습했음. -> 트랜스포머의 디코더와 구조 일치함.
- 현재까지의 단어 시퀀스를 이용해서 다음 단어를 예측하는 작업은, 그 이후 단어들로부터 오는 어텐션을 활용할 수 없음
- BERT는 양방향 셀프 어텐션 인코더로 어떻게 언어 모델을 학습하나?
-> masking!
masked language model:
- 가려진 단어는 문장의 중간에 위치하며, 양쪽에 단어들이 있어 양방향 셀프 어텐션을 모두 이용해 예측하는 것이 가능
+ 두 개의 문장을 다룰 수 있도록 하는 것!
- 트랜스포머는 인코더와 디코더로 구성돼 있어, 두 문장을 다뤄야 하는 경우에 하나는 인코더로 다른 하나는 디코더로 보내는 것을 자연스럽게 생각할 수 있음.
-> BERT의 아이디어는 두 문장을 구분하는 토큰을 정의하고 두 문장 사이에 넣어서 하나의 시퀀스를 만든 후에 인코더에서 한 번에 처리하도록 하는 것임.
- A와 B 두 문장을 주고 순서가 올바른지 거꾸로인지를 예측 -> 주어진 목표에 맞게 학습을 하는 미세조정학습
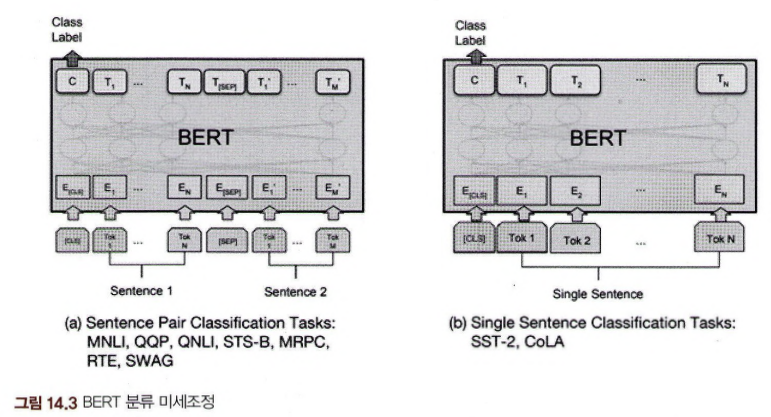
14.5 사전학습된 BERT 모형의 직접 사용방법
BERT는 사전학습된 모형을 전이학습으로 활용할 수 있다는 점이 가장 매력적임
transformers 라이브러리를 사용하는 가장 쉬운 방법은 파이프라인(pipeline)을 이용하는 것




14.6 자동 클래스를 이용한 토크나이저와 모형의 사용
라이브러리가 제공하는 자동 클래스(Auto Classes)를 사용해서 자동으로 적절한 토크나이저와 모형을 선택하게 할 수 있음
- 트랜스포머는 딥러닝 연산을 위한 백엔드로 파이토치와 텐서플로 모두 사용할 수 있음
-> 둘 다 센터에 대한 연산과 기본적으로 동일한 딥러닝 단계 지원 (이 책에서는 파이토치 사용)
- mrpc: The Microsoft Research Paraphrase Corpus
의미적으로 유사한 문장의 페어와 그렇지 않은 문장의 페어로 구성해서 두 문장의 의미적 유사성을 학습할 수 있도록 만든 데이터셋


- 테스트를 위해 의미적으로 유사한 두 문장을 정의함. target_sequence 는 input_Sentence의 내용을 요약하는 형태
- > 모형이 제대로 작동한다면 두 문장의 의미족 유사성이 높다고 할 것임.


-> NLTK의 영화 리뷰는 길이가 길어서 위에서 사용한 감성분석 파이프라인을 쓰면 에러가 발생함
- 본격적으로 BERT를 이용 & 테스트 데이터셋이 여러 개로 이뤄졌으므로 배치로 처리할수 있어야 함.
10개씩 잘라서 모형을 돌리고 결과를 합쳐서 성능 살펴보기.

